
@AutoTLDR
12
cross-posted from: https://programming.dev/post/400779
24
cross-posted from: https://programming.dev/post/400779
Seems like it isn’t:
the same technology under the hood of Google Translate
This is incredible, thanks for sharing it!
If I remember correctly, the properties the API returns are comment_score and post_score.
Lemmy does have karma, it is stored in the DB, and the API returns it. It just isn’t displayed on the UI.
It definitely helps me. It isn’t perfect, but it’s a night and day difference
I’ve found that after using it for a while, I developed a feel for the complexity of the tasks it can handle. If I aim below this level, its output is very good most of the time. But I have to decompose the problem and make it solve the subproblems one by one.
(The complexity ceiling is much higher for GPT-4, so I use it almost exclusively.)
It only handles HTML currently, but I like your idea, thank you! I’ll look into implementing reading PDFs as well. One problem with scientific articles however is that they are often quite long, and they don’t fit into the model’s context. I would need to do recursive summarization, which would use much more tokens, and could become pretty expensive. (Of course, the same problem occurs if a web page is too long; I just truncate it currently which is a rather barbaric solution.)
someone watching you code in a google doc
I’ve had nightmares less terrifying than this
It may very well be related to it.
49
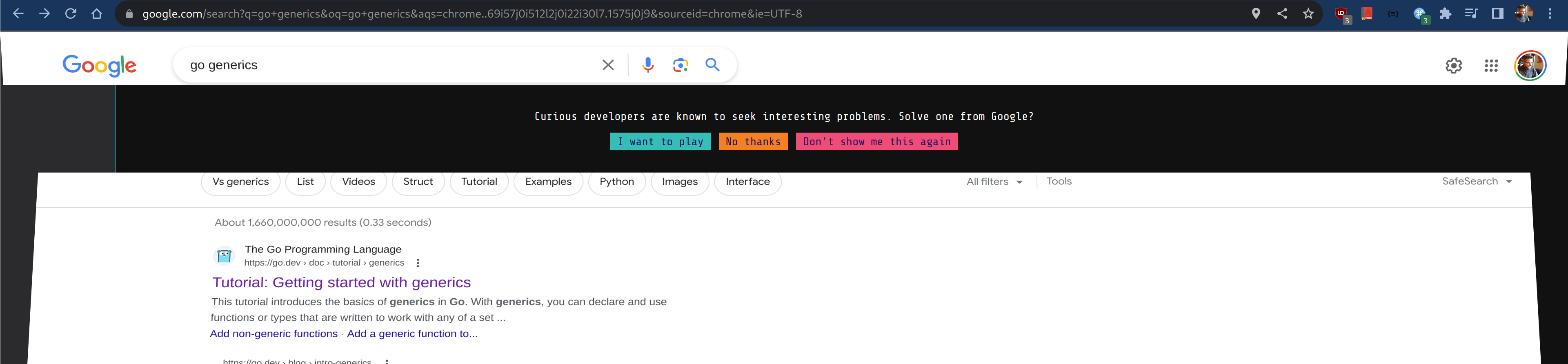
Has anyone else seen this interesting "challenge site" when googling a programming topic?
(programming.dev)
I looked it up (on Google of course) and it seems like this is one of Google's recruitment channels.
You get access to a terminal and a text editor:

Here are the commands you can execute:

You have a week to complete each challenge. I've done 2 of them so far, and requested the third one - they have been very enjoyable and I've already learnt a lot from them.
I'm pretty sure I have literally zero chance of being hired by Google (and I'm not even sure I would want to work for them even if they made the mistake of wanting to hire me), but this has been super interesting so far. And yeah, also a huge time waster, I've been thinking about making the solution to the third challenge more elegant and performant all day instead of doing my actual job.
20
Douglas Hofstadter changes his mind on Deep Learning & AI risk (June 2023)? — LessWrong
(www.lesswrong.com)
Looks like you have a problem with extracting just the README from GitHub. Let's see if you can read the raw link: https://raw.githubusercontent.com/0xpayne/gpt-migrate/main/README.md