It’s a Node.js app because the Lemmy-bot library is for Node.
I will definitely open source it, but the code is currently in a disgusting state, so I need to clean it up first.
It’s a Node.js app because the Lemmy-bot library is for Node.
I will definitely open source it, but the code is currently in a disgusting state, so I need to clean it up first.
It’s still in preview, I can’t access it either, only a select few on Twitter who post about it all the time and make me jealous:)
Yes, OpenAI and out of pocket. Unfortunately cheaper or self-hosted models are much worse.
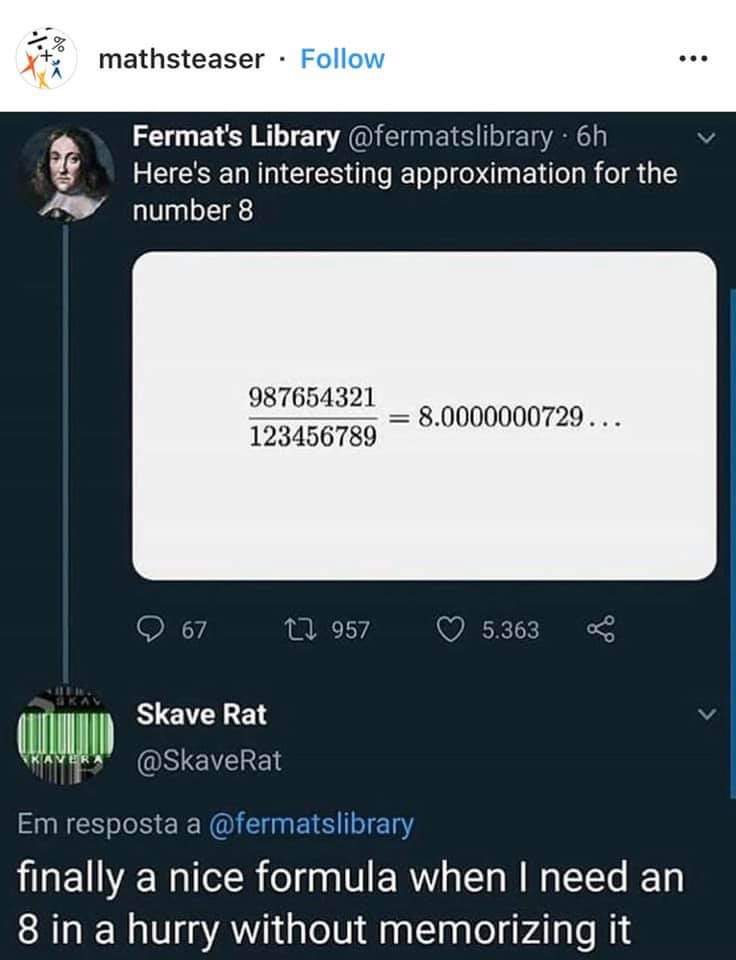
Thank you, that’s a reasonable suggestion, I added it to the comment template:
TL;DR: (AI-generated 🤖)
Yes, they have promised explicitly not to use API data for training.
Thank you, I’ll take a look at these models, I hope I can find something a bit cheaper but still high-quality.
Unfortunately I don’t yet have access to it so I can’t check if the description always comes first. But your theory sounds interesting, I hope we’ll be able to find out more soon.
3.5 is also really good, but I've been using GPT-4 for almost everything since it became available. 3.5 hallucinates more often but I used it a lot before April, and I was really satisfied with it.
I implemented it. The feature will be available right from the start. The bot will reply this if the user has disabled it:
🔒 The author of this post or comment has the #nobot hashtag in their profile. Out of respect for their privacy settings, I am unable to summarize their posts or comments.
It will be me 😭
I limited it to 100 summaries per day, so it won’t cost more than about $20/month in the worst case.
I haven’t yet looked into it, but the screencast on its website looks really promising! I have a lot on my plate right now so I think I’ll release it first with the GPT-3.5 integration, but I’ll definitely try GPT4All later!
It can also summarize links, so it’s already useful even if there are few people posting walls of text


Finally I could get into the beta and all I can say is wow, I’m in love with this app 🤩
Keep up the good work!