If you visit a popular community like /c/memes@lemmy.ml with your web browser, the images shown are hotlinked from the Lemmy instance that the person posting the image utilized. This means that your browser makes a https request to that remote server, not your local instance, giving that server your IP address and web browser version string.
Assume that it is not difficult for someone to compile this data and build a profile of your browsing habits and patterns of image fetching - and is able to identify with high probability which comments and user account is being used on the remote instance (based on timestamp comparison).
For example, if you are a user on lemmy.ml browsing the local community memes, you see postings like these first two I see right now:
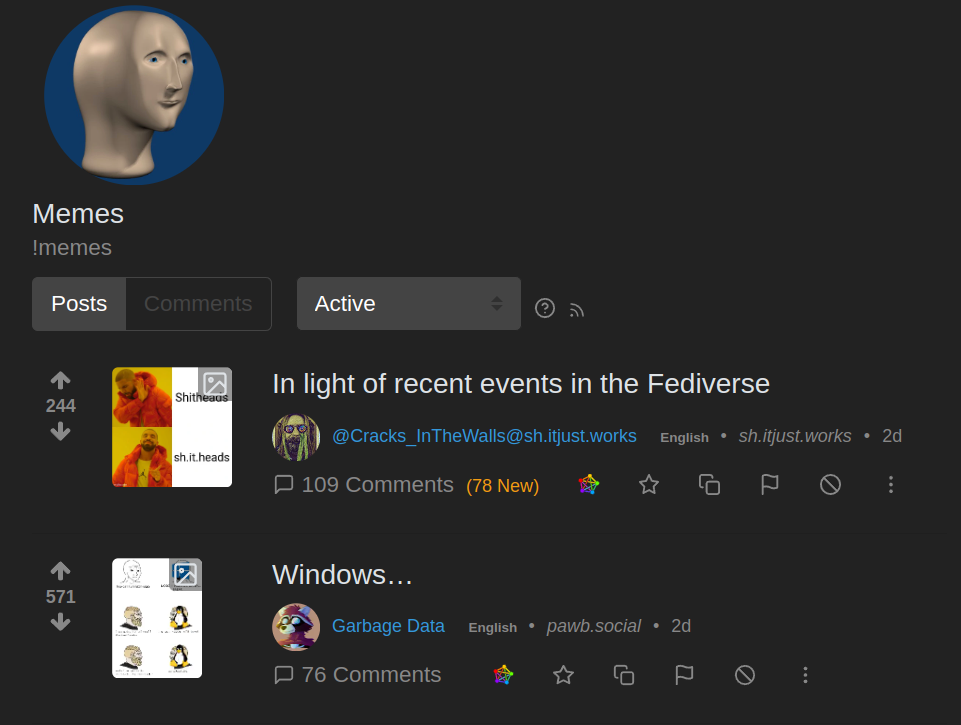
You can see that the 2nd one has a origin of pawb.social - and that thumbnail was loaded from a sever on that remote site:
https://pawb.social/pictrs/image/fc4389aa-bd4f-4406-bfd6-d97d41a3324e.webp?format=webp&thumbnail=256
{kind=link}
Just browsing a list of memes you are giving out your IP address and browser string to dozens of Lemmy servers hosted by anonymous owner/operators.
Each instance with an owner/operator making rules... that the average social media user walks in, orders a drink, and starts smoking without any concern that neither one may be allowed. People can be loyal to their media outlets even when it is beyond obvious they are bad. People raised on storybooks that endorse bad behaviors and values, HDTV networks, and social media too. Audience desire to "react comment" to images and not actually read what others have commented - nor learn about the venue operators and reasons for rules is pretty much the baseline experience in 2023.