1676
Technology
34832 readers
1 users here now
This is the official technology community of Lemmy.ml for all news related to creation and use of technology, and to facilitate civil, meaningful discussion around it.
Ask in DM before posting product reviews or ads. All such posts otherwise are subject to removal.
Rules:
1: All Lemmy rules apply
2: Do not post low effort posts
3: NEVER post naziped*gore stuff
4: Always post article URLs or their archived version URLs as sources, NOT screenshots. Help the blind users.
5: personal rants of Big Tech CEOs like Elon Musk are unwelcome (does not include posts about their companies affecting wide range of people)
6: no advertisement posts unless verified as legitimate and non-exploitative/non-consumerist
7: crypto related posts, unless essential, are disallowed
founded 6 years ago
MODERATORS
1677
1678
0
New ROCm™ 5.6 Release Brings Enhancements and Optimizations for AI and HPC Workloads
(community.amd.com)
1679
1680
1681
1682
1683
1684
1685
21
North Carolina soon a broke state - vote on a bill to study "potential benefits" of holding Bitcoin among other assets
(lemmy.world)
Transcription below
A BILL TO BE ENTITLED
AN ACT TO STUDY THE HOLDING OF BULLION AND VIRTUAL CURRENCY AND THEIR POTENTIAL BENEFITS AND WHETHER TO ESTABLISH A NORTH CAROLINA BULLION DEPOSITORY FOR SUCH ASSETS.
The General Assembly of North Carolina enacts: SECTION 1. The Department of State Treasurer shall conduct a study that examines (i) the process of acquiring, securely storing, insuring, and liquidating any investment metal bullion as defined in G.S. 105-164.13(69), such as gold, and virtual currency as defined in G.S. 53-208.42(20), such as Bitcoin, that may be held on behalf of the State, (ii) the expected impact of allocating a portion of the General Fund to investment metal bullion and virtual currency to hedge against inflation and systemic credit risks, reduce overall portfolio volatility, and increase portfolio returns over time, and (iii) the costs, benefits, and security of utilizing a privately managed depository or another state's depository or creating a State-administered depository in North Carolina to serve as the custodian, guardian, and administrator of certain investment metal bullion and virtual currency that may be transferred to or otherwise acquired by this State or an agency, a political subdivision, or another instrumentality of this State and to provide a repository for investors to use for such assets. The Department of State Treasurer shall 18 report on the results of the study, along with any legislative or other recommendations, to the 19 Joint Legislative Commission on Governmental Operations by January 1, 2024.
SECTION 2. There is appropriated from the General Fund to the Department of State Treasurer the nonrecurring sum of fifty thousand dollars ($50,000) for the 2023-2024 fiscal year to conduct the study required by this act.
SECTION 3. Section 2 of this act becomes effective July 1, 2023. The remainder of 24 this act is effective when it becomes law.

1686
1687
1688
1689
1690
1691
135
More anti-Lemmy brigading with massive upvotes on Reddit as the 3rd party app apocalypse looms
(lemmy.world)
Guess where? Unironically r/Save3rdPartyApps
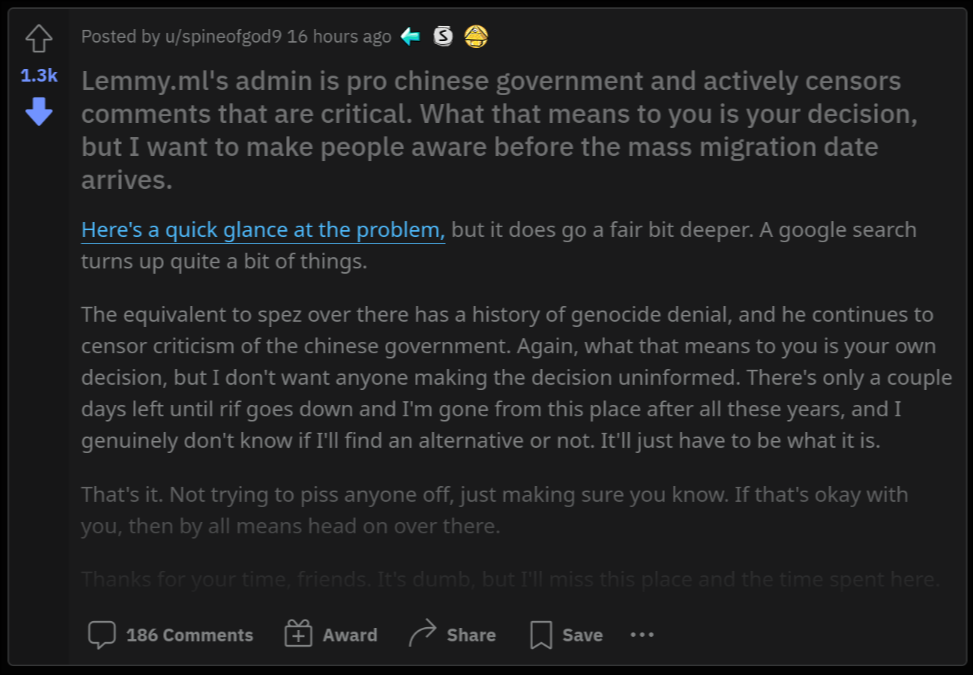
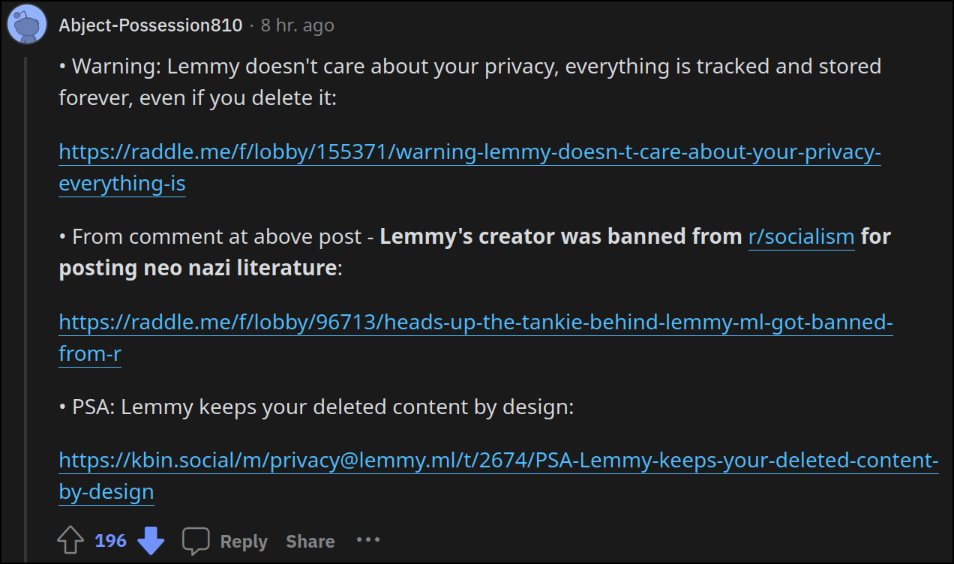
The Reddit search for Lemmy also gives these privacy copy-pasta as top results when searching for Lemmy. I'm still betting that Reddit employees are involved in boosting these posts.
1693
1694
1695
1696
1697
1698
1699
1700