1526
Technology
34832 readers
1 users here now
This is the official technology community of Lemmy.ml for all news related to creation and use of technology, and to facilitate civil, meaningful discussion around it.
Ask in DM before posting product reviews or ads. All such posts otherwise are subject to removal.
Rules:
1: All Lemmy rules apply
2: Do not post low effort posts
3: NEVER post naziped*gore stuff
4: Always post article URLs or their archived version URLs as sources, NOT screenshots. Help the blind users.
5: personal rants of Big Tech CEOs like Elon Musk are unwelcome (does not include posts about their companies affecting wide range of people)
6: no advertisement posts unless verified as legitimate and non-exploitative/non-consumerist
7: crypto related posts, unless essential, are disallowed
founded 6 years ago
MODERATORS
1527
261
Musk says a 50% drop in ad revenue for Twitter is causing negative cash flow
(www.phonearena.com)
1528
1529
1530
1531
1532
1533
1534
cross-posted from: https://lemmy.world/post/1535820
I'd like to share with you Petals: decentralized inference and finetuning of large language models
- https://petals.ml/
- https://research.yandex.com/blog/petals-decentralized-inference-and-finetuning-of-large-language-models
Run large language models at home, BitTorrent‑style
Run large language models like LLaMA-65B, BLOOM-176B, or BLOOMZ-176B collaboratively — you load a small part of the model, then team up with people serving the other parts to run inference or fine-tuning. Single-batch inference runs at 5-6 steps/sec for LLaMA-65B and ≈ 1 step/sec for BLOOM — up to 10x faster than offloading, enough for chatbots and other interactive apps. Parallel inference reaches hundreds of tokens/sec. Beyond classic language model APIs — you can employ any fine-tuning and sampling methods, execute custom paths through the model, or see its hidden states. You get the comforts of an API with the flexibility of PyTorch.
Overview of the Approach
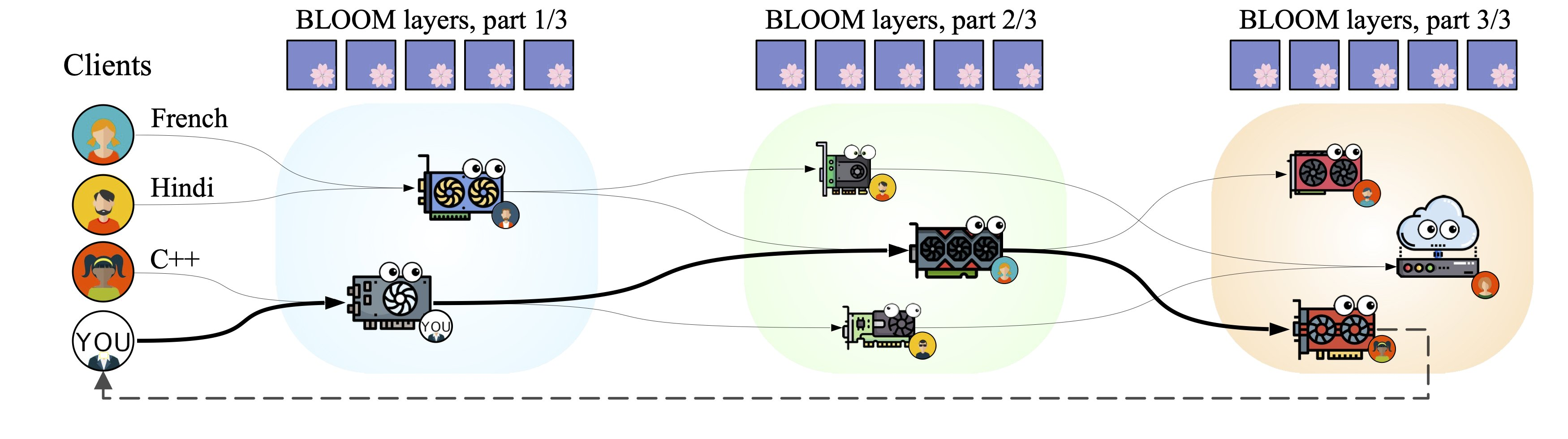
On a surface level, Petals works as a decentralized pipeline designed for fast inference of neural networks. It splits any given model into several blocks (or layers) that are hosted on different servers. These servers can be spread out across continents, and anybody can connect their own GPU! In turn, users can connect to this network as a client and apply the model to their data. When a client sends a request to the network, it is routed through a chain of servers that is built to minimize the total forward pass time. Upon joining the system, each server selects the most optimal set of blocks based on the current bottlenecks within the pipeline. Below, you can see an illustration of Petals for several servers and clients running different inputs for the model.
Benchmarks
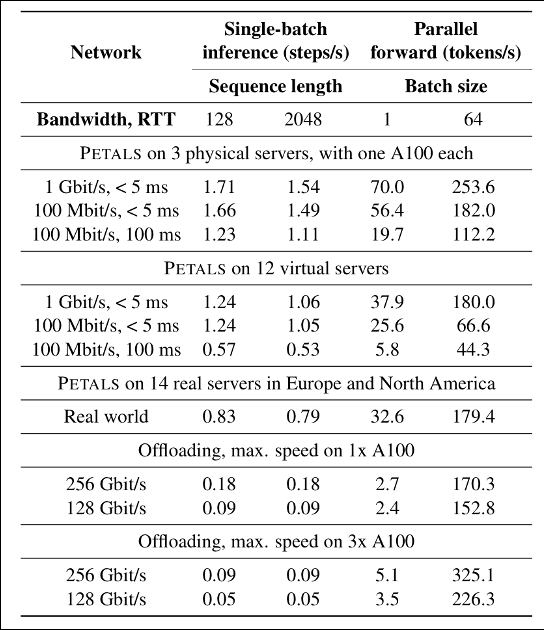
We compare the performance of Petals with offloading, as it is the most popular method for using 100B+ models on local hardware. We test both single-batch inference as an interactive setting and parallel forward pass throughput for a batch processing scenario. Our experiments are run on BLOOM-176B and cover various network conditions, from a few high-speed nodes to real-world Internet links. As you can see from the table below, Petals is predictably slower than offloading in terms of throughput but 3–25x faster in terms of latency when compared in a realistic setup. This means that inference (and sometimes even finetuning) is much faster with Petals, despite the fact that we are using a distributed model instead of a local one.
Conclusion
Our work on Petals continues the line of research towards making the latest advances in deep learning more accessible for everybody. With this work, we demonstrate that it is feasible not only to train large models with volunteer computing, but to run their inference in such a setup as well. The development of Petals is an ongoing effort: it is fully open-source (hosted at https://github.com/bigscience-workshop/petals), and we would be happy to receive any feedback or contributions regarding this project!
1535
1536
1537

1538
62
Wireshark Is 25: The email that started it all and lessons learned along the way
(blog.wireshark.org)
1539
1540
1541
1542
1543
1544
1545
1546

1548
1549
1550