1501
Technology
34832 readers
1 users here now
This is the official technology community of Lemmy.ml for all news related to creation and use of technology, and to facilitate civil, meaningful discussion around it.
Ask in DM before posting product reviews or ads. All such posts otherwise are subject to removal.
Rules:
1: All Lemmy rules apply
2: Do not post low effort posts
3: NEVER post naziped*gore stuff
4: Always post article URLs or their archived version URLs as sources, NOT screenshots. Help the blind users.
5: personal rants of Big Tech CEOs like Elon Musk are unwelcome (does not include posts about their companies affecting wide range of people)
6: no advertisement posts unless verified as legitimate and non-exploitative/non-consumerist
7: crypto related posts, unless essential, are disallowed
founded 6 years ago
MODERATORS
1502
1503
1504
13
cross-posted from: https://lemmy.world/post/1750098
Introducing Llama 2 - Meta's Next Generation Free Open-Source Artificially Intelligent Large Language Model
It's incredible it's already here! This is great news for everyone in free open-source artificial intelligence.
Llama 2 unleashes Meta's (previously) closed model (Llama) to become free open-source AI, accelerating access and development for large language models (LLMs).
This marks a significant step in machine learning and deep learning technologies. With this move, a widely supported LLM can become a viable choice for businesses, developers, and entrepreneurs to innovate our future using a model that the community has been eagerly awaiting since its initial leak earlier this year.
Here are some highlights from the official Meta AI announcement:
Llama 2
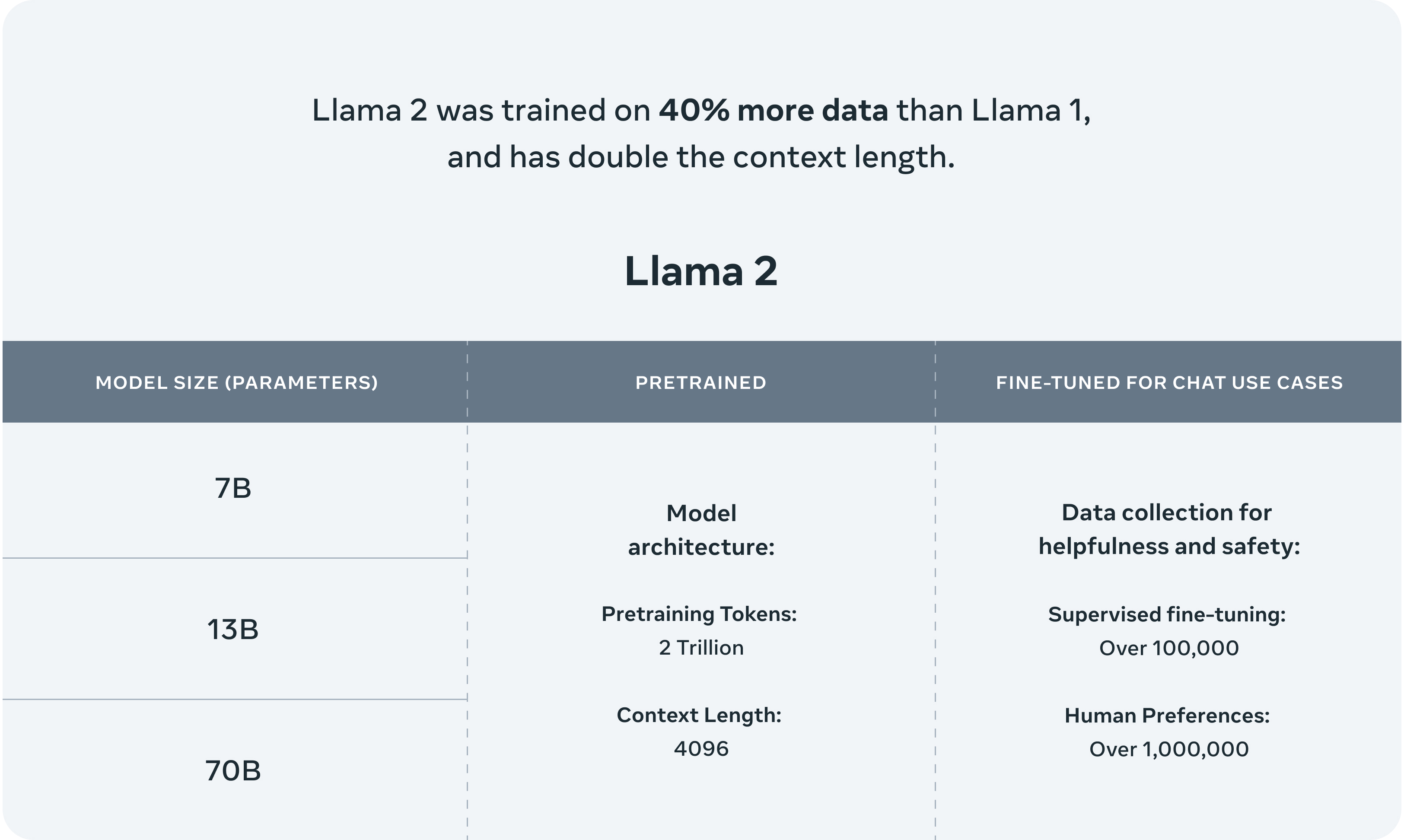
In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases.
Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closedsource models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
Llama 2 pretrained models are trained on 2 trillion tokens, and have double the context length than Llama 1. Its fine-tuned models have been trained on over 1 million human annotations.
Inside the Model
With each model download you'll receive:
- Model code
- Model Weights
- README (User Guide)
- Responsible Use Guide
- License
- Acceptable Use Policy
- Model Card
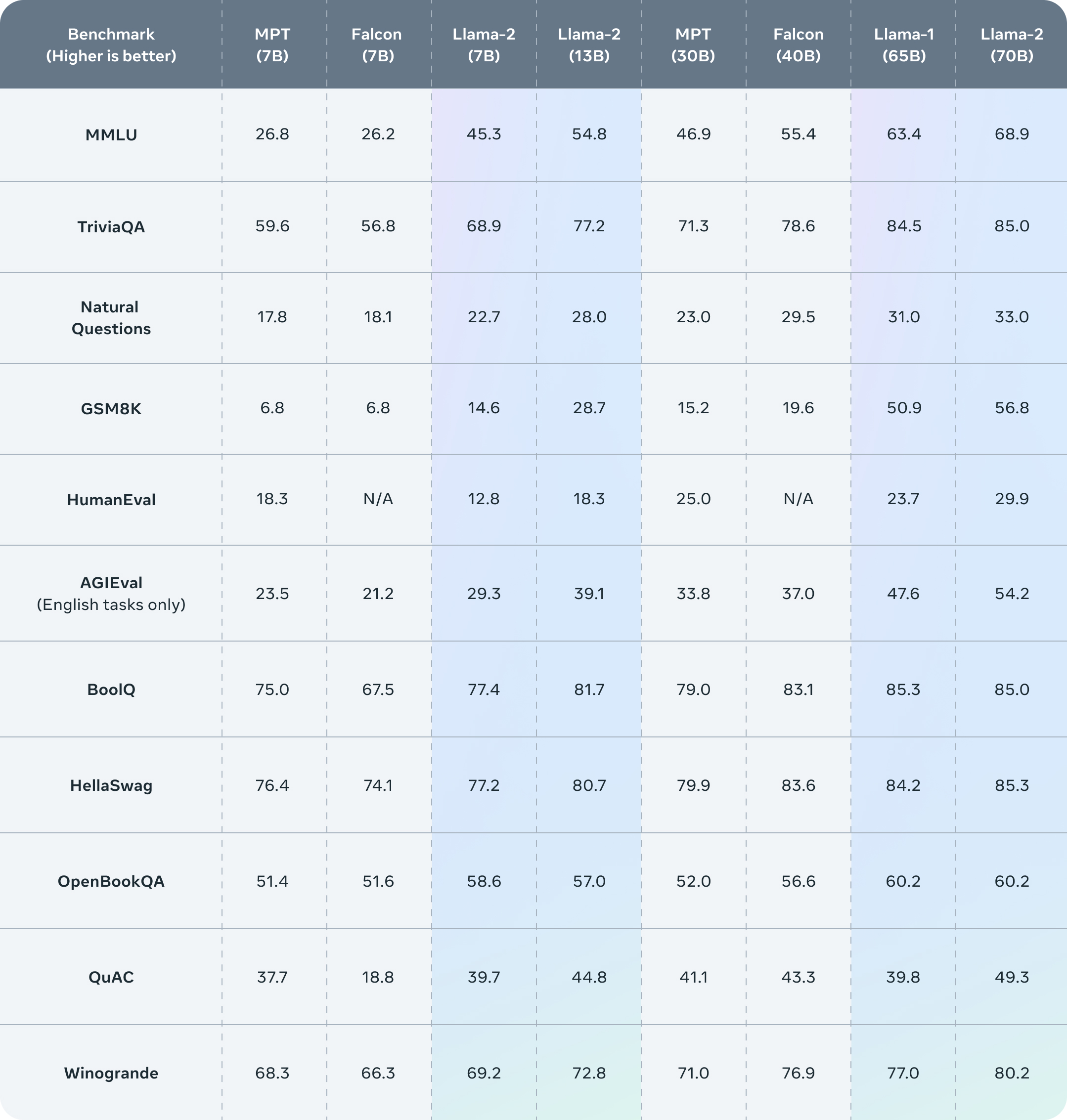
Benchmarks
Llama 2 outperforms other open source language models on many external benchmarks, including reasoning, coding, proficiency, and knowledge tests. It was pretrained on publicly available online data sources. The fine-tuned model, Llama-2-chat, leverages publicly available instruction datasets and over 1 million human annotations.
RLHF & Training
Llama-2-chat uses reinforcement learning from human feedback to ensure safety and helpfulness. Training Llama-2-chat: Llama 2 is pretrained using publicly available online data. An initial version of Llama-2-chat is then created through the use of supervised fine-tuning. Next, Llama-2-chat is iteratively refined using Reinforcement Learning from Human Feedback (RLHF), which includes rejection sampling and proximal policy optimization (PPO).

The License
Our model and weights are licensed for both researchers and commercial entities, upholding the principles of openness. Our mission is to empower individuals, and industry through this opportunity, while fostering an environment of discovery and ethical AI advancements.
Partnerships
We have a broad range of supporters around the world who believe in our open approach to today’s AI — companies that have given early feedback and are excited to build with Llama 2, cloud providers that will include the model as part of their offering to customers, researchers committed to doing research with the model, and people across tech, academia, and policy who see the benefits of Llama and an open platform as we do.
The/CUT
With the release of Llama 2, Meta has opened up new possibilities for the development and application of large language models. This free open-source AI not only accelerates access but also allows for greater innovation in the field.
Take Three:
- Video Game Analogy: Just like getting a powerful, rare (or previously banned) item drop in a game, Llama 2's release gives developers a powerful tool they can use and customize for their unique quests in the world of AI.
- Cooking Analogy: Imagine if a world-class chef decided to share their secret recipe with everyone. That's Llama 2, a secret recipe now open for all to use, adapt, and improve upon in the kitchen of AI development.
- Construction Analogy: Llama 2 is like a top-grade construction tool now available to all builders. It opens up new possibilities for constructing advanced AI structures that were previously hard to achieve.
Links
Here are the key resources discussed in this post:
Want to get started with free open-source artificial intelligence, but don't know where to begin?
Try starting here:
If you found anything else about this post interesting - consider subscribing to !fosai@lemmy.world where I do my best to keep you in the know about the most important updates in free open-source artificial intelligence.
This particular announcement is exciting to me because it may popularize open-source principles and practices for other enterprises and corporations to follow.
We should see some interesting models emerge out of Llama 2. I for one am looking forward to seeing where this will take us next. Get ready for another wave of innovation! This one is going to be big.
1505
1506
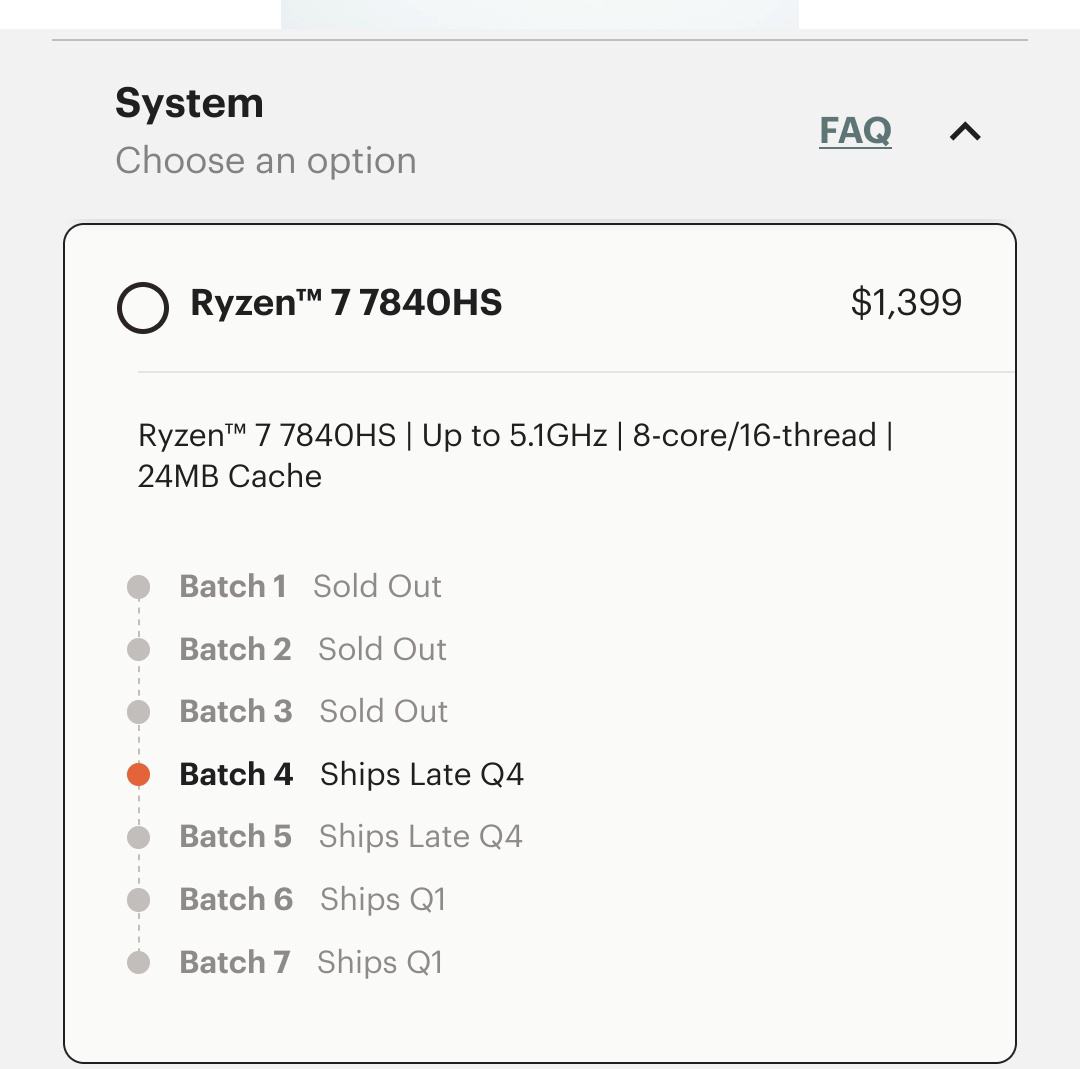
Image description: Image shows batches 1, 2 and 3 sold out for the Ryzen 7 7840HS which costs $1,399.
cross-posted from: https://mander.xyz/post/1226322
For now both DIY and prebuild edition (all configurations) are in batch 4 which ships in late Q4 2023.
1507
1508
1509
104
Microsoft to face EU competition investigation over Teams and Office bundling
(www.irishtimes.com)
1510
1511
1512
1513
1514
1515
1516
1517
1518
10
New AI/LLM Breakthrough - FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
(lemmy.world)
cross-posted from: https://lemmy.world/post/1709025
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
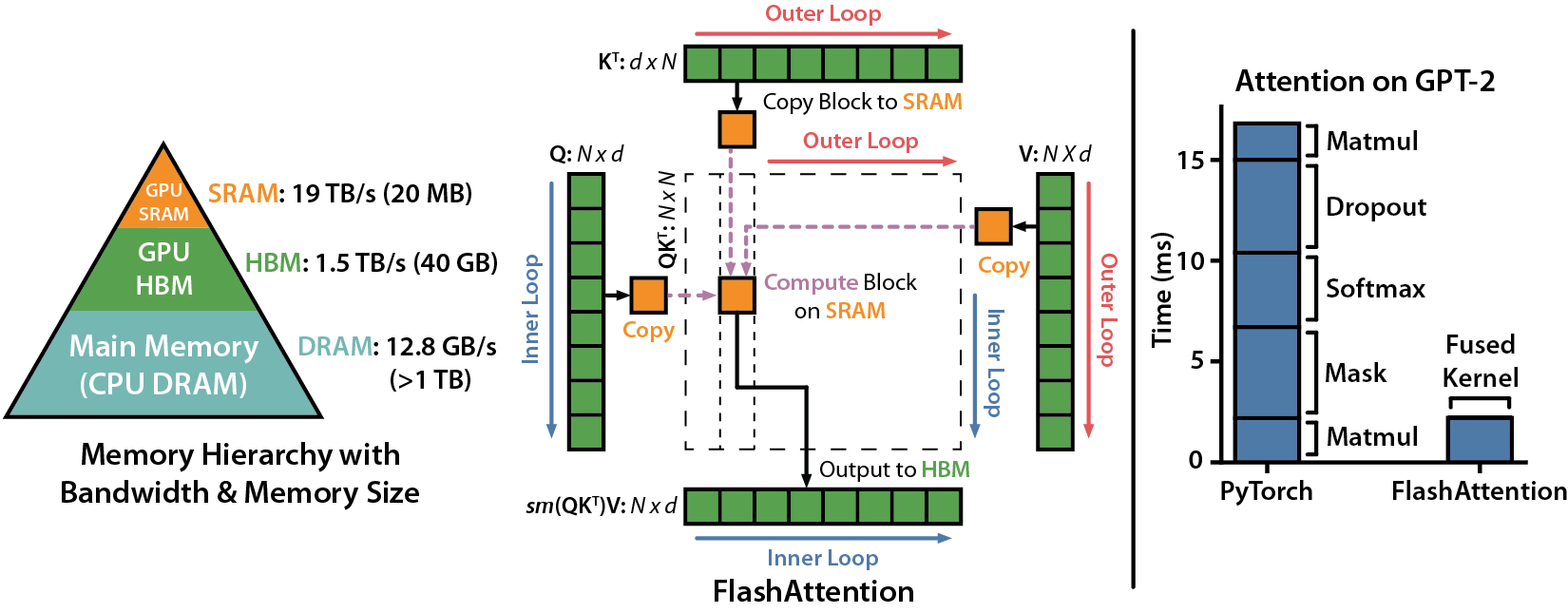
Today, we explore an exciting new development: FlashAttention-2, a breakthrough in Transformer model scaling and performance. The attention layer, a key part of Transformer model architecture, has been a bottleneck in scaling to longer sequences due to its runtime and memory requirements. FlashAttention-2 tackles this issue by improving work partitioning and parallelism, leading to significant speedups and improved efficiency for many AI/LLMs.
The significance of this development is huge. Transformers are fundamental to many current machine learning models, used in a wide array of applications from language modeling to image understanding and audio, video, and code generation. By making attention algorithms IO-aware and improving work partitioning, FlashAttention-2 gets closer to the efficiency of General Matrix to Matrix Multiplication (GEMM) operations, which are highly optimized for modern GPUs. This enables the training of larger and more complex models, pushing the boundaries of what's possible with machine learning both at home and in the lab.
Features & Advancements
FlashAttention-2 improves upon its predecessor by tweaking the algorithm to reduce the number of non-matrix multiplication FLOPs, parallelizing the attention computation, and distributing work within each thread block. These improvements lead to approximately 2x speedup compared to FlashAttention, reaching up to 73% of the theoretical maximum FLOPs/s.
Relevant resources:
Installation & Requirements
To install FlashAttention-2, you'll need CUDA 11.4 and PyTorch 1.12 or above. The installation process is straightforward and can be done through pip or by compiling from source. Detailed instructions are provided on the Github page.
Relevant resources:
Supported Hardware & Datatypes
FlashAttention-2 currently supports Ampere, Ada, or Hopper GPUs (e.g., A100, RTX 3090, RTX 4090, H100). Support for Turing GPUs (T4, RTX 2080) is coming soon. It supports datatype fp16 and bf16 (bf16 requires Ampere, Ada, or Hopper GPUs). All head dimensions up to 256 are supported.
Relevant resources:
The/CUT
FlashAttention-2 is a significant leap forward in Transformer model scaling. By improving the efficiency of the attention layer, it allows for faster and more efficient training of larger models. This opens up new possibilities in machine learning applications, especially in systems or projects that need all the performance they can get.
Take Three: Three big takeaways from this post:
Performance Boost: FlashAttention-2 is a significant improvement in Transformer architecture and provides a massive performance boost to AI/LLM models who utilize it. It manages to achieve a 2x speedup compared to its predecessor, FlashAttention. This allows for faster training of larger and more complex models, which can lead to breakthroughs in various machine learning applications at home (and in the lab).
Efficiency and Scalability: FlashAttention-2 improves the efficiency of attention computation in Transformers by optimizing work partitioning and parallelism. This allows the model to scale to longer sequence lengths, increasing its applicability in tasks that require understanding of larger context, such as language modeling, high-resolution image understanding, and code, audio, and video generation.
Better Utilization of Hardware Resources: FlashAttention-2 is designed to be IO-aware, taking into account the reads and writes between different levels of GPU memory. This leads to better utilization of hardware resources, getting closer to the efficiency of optimized matrix-multiply (GEMM) operations. It currently supports Ampere, Ada, or Hopper GPUs and is planning to extend support for Turing GPUs soon. This ensures that a wider range of machine learning practitioners and researchers can take advantage of this breakthrough.
Links
If you found anything about this post interesting - consider subscribing to !fosai@lemmy.world where I do my best to keep you informed in free open-source artificial intelligence.
Thank you for reading!
1519
1520
1521
1522
1523
1524
1525