3126
Piracy: ꜱᴀɪʟ ᴛʜᴇ ʜɪɢʜ ꜱᴇᴀꜱ
64175 readers
540 users here now
⚓ Dedicated to the discussion of digital piracy, including ethical problems and legal advancements.
Rules • Full Version
1. Posts must be related to the discussion of digital piracy
2. Don't request invites, trade, sell, or self-promote
3. Don't request or link to specific pirated titles, including DMs
4. Don't submit low-quality posts, be entitled, or harass others

Loot, Pillage, & Plunder
📜 c/Piracy Wiki (Community Edition):
🏴☠️ Other communities
FUCK ADOBE!
Torrenting/P2P:
- !seedboxes@lemmy.dbzer0.com
- !trackers@lemmy.dbzer0.com
- !qbittorrent@lemmy.dbzer0.com
- !libretorrent@lemmy.dbzer0.com
- !soulseek@lemmy.dbzer0.com
Gaming:
- !steamdeckpirates@lemmy.dbzer0.com
- !newyuzupiracy@lemmy.dbzer0.com
- !switchpirates@lemmy.dbzer0.com
- !3dspiracy@lemmy.dbzer0.com
- !retropirates@lemmy.dbzer0.com
💰 Please help cover server costs.
 |
 |
|---|---|
| Ko-fi | Liberapay |
founded 2 years ago
MODERATORS
3127
3128
3129
3130
3131
3132
3133
3134
3135
3136
3137
3138
3139
3140
3141
3142
3143
3144
3145
3146
3147
49
UFW (Uncomplicated Firewall) with Wireguard connecting to Mullvad VPN sanity check on UFW setup.
(lemmy.world)
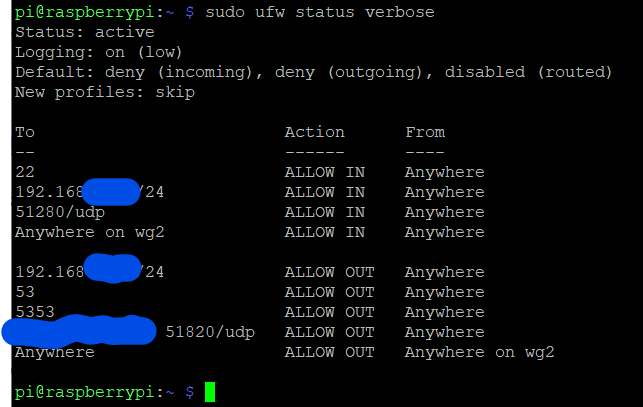
I would really appreciate it if someone would double check me. Sorry for the screenshot. Either the Lemmy code button isn't great or I'm just dum at formatting.
This has local *arr servers available and traceroute shows me going through the VPN.
The largest blue blotch is the ip address of a mullvad vpn server.
Rpi4, Raspberry Pi OS lite.
Mullvad VPN. IPv6 has been nuked. Using Wireguard through wg-quick.
wg2 originates from a .conf file from Mullvad with IPv6 stripped.
Do these UFW settings look right?
3148
3149
3150